

tldr: I wrote a Pandoc Lua filter to correctly format my Bookdown/Rmarkdown documents no matter the output file. You can see the filter as a Github gist here.
Apparently I’m never satisfied enough to stop futzing around with Bookdown. I’ve been twiddling and tweaking settings endlessly to see what kind of documents I can produce and, more importantly, how I can get similar results across a number of formats.
In the process, I’ve fallen over some really useful discoveries. They’re usually well-documented discoveries and mostly right there, out in the open, but for some reason I don’t see them talked about much despite their incredible usefulness!
Among these, number #1 with a bullet is the use of Pandoc’s custom filters to modify your source document. These are amazing. They’re basically ways of changing the output from Pandoc based on some logic, such as the output format. So I thought I’d talk about them a little bit here, and explain how I’ve put them to good use.
Pandoc filters
You can use JSON manipulation in any code language you prefer to do this, or write the filter in Lua. I chose to use Lua (despite not knowing Lua) because Pandoc includes a Lua interpreter embedded in it, so you don’t need any external dependencies. Fortunately, some Lua basics weren’t too hard to pick up, but please excuse my shoddy Lua coding in the examples given.
I think a diagram will help explain how filters work with Pandoc. Normally, building your book in Bookdown/Rmarkdown looks like this:
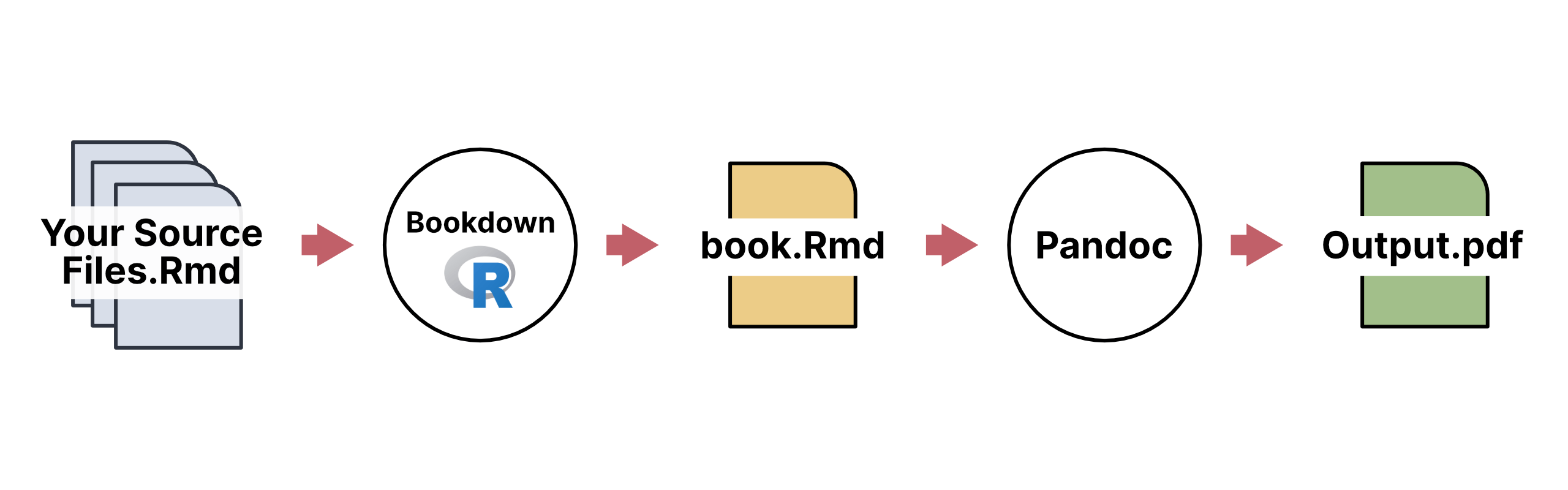
You write all your source docs, Bookdown/R processes all your code to produce plots/tables/etc and compiles all that into one mega-source doc, then ships that over to Pandoc with all your Bookdown options to produce your final output file (pdf/html/what-have-you).
With a filter, there is an extra step in the middle of the Pandoc circle. Under the hood, Pandoc reads in the input doc (book.Rmd in our case) and turns it into Pandoc’s own interstitial format (an ‘abstract syntax tree’ or AST). Normally this then gets written straight back out into your desired output format.
But! With a filter, you get a chance to jump in and apply some logic to the AST, before it then gets sent over to the writer for the output format.
So, let’s say we wanted to change something in the original source document based on whether we are creating a PDF or HTML document. Using a filter, we can create something this:
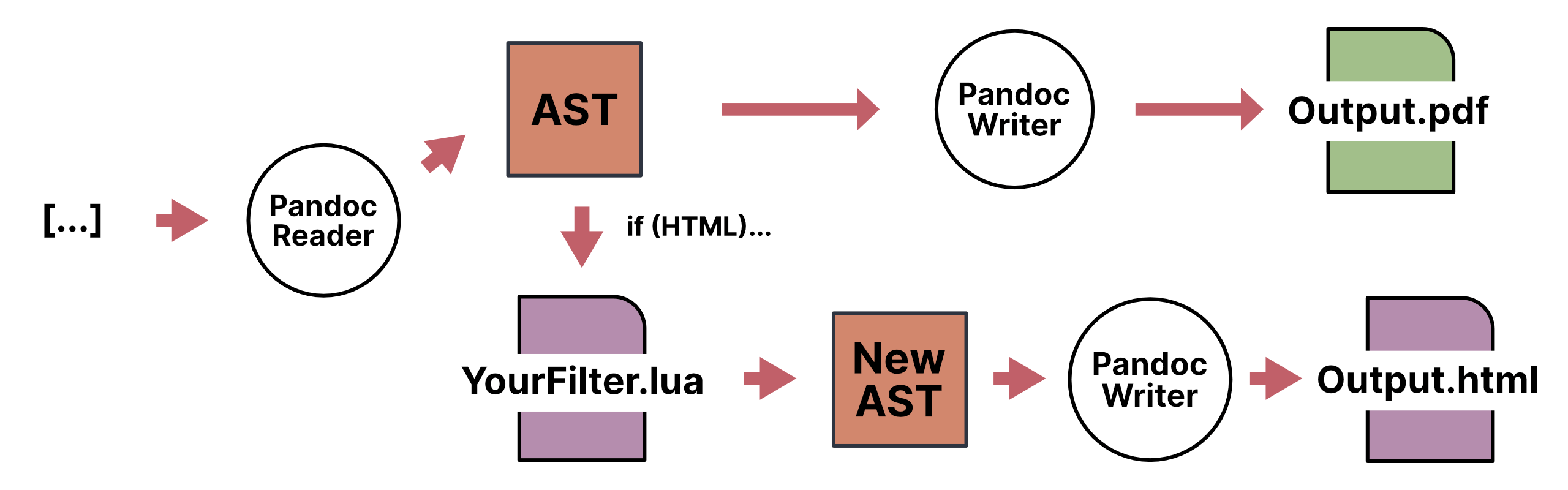
This gives you a chance to affect elements of your document independent of any input/output foibles, and most usefully, change what output Pandoc’s writer will generate based on whatever criteria you define. 1
Writing the filter
Writing the filter is not super complicated, and the docs are very comprehensive, but it can take a second to wrap your head around how it works. Essentially, the filter should consist of a function named for one of the elements of Pandoc’s AST. Which is just another way of saying, the elements of your source document.
So, if you want to affect all the Strong elements of your document, you would write a function named “Strong” and pass it the element as an argument - Strong(elem). Pandoc will ‘walk’ the AST with your filter, and every time it finds a Strong element 2, apply your filter function to the contents of it (elem).
The only caveat is that a function must return the same type of element that went into it - so for Strong elements, the function Strong() must return an Inline element. Some elements are Block elements, like entire paragraphs or divs, that must also return a Block.
This can be a bit finicky but basically, if the element can appear in the middle of a sentence, it’s probably an Inline. If the element is a collection of smaller elements, it’s probably a Block.
Example
Here’s a practical example. I like to use Pandoc’s fenced div syntax to define little breakout boxes of information in my documents. Here’s the syntax in my source Markdown file:
# Heading
Some text goes here.
::: notes
Here's the content of my breakout box.
:::
Pandoc already processes this into HTML, resulting in the following output:
<h1>Heading</h1>
<p>Some text goes here.</p>
<div class="notes">
<p>Here's the content of my breakout box.</p>
</div>
Notice how Pandoc has spotted our ’notes’ label on the paragraph in the Markdown and automatically applied it as a class to the div in the HTML. With a little CSS, this div then shows as:
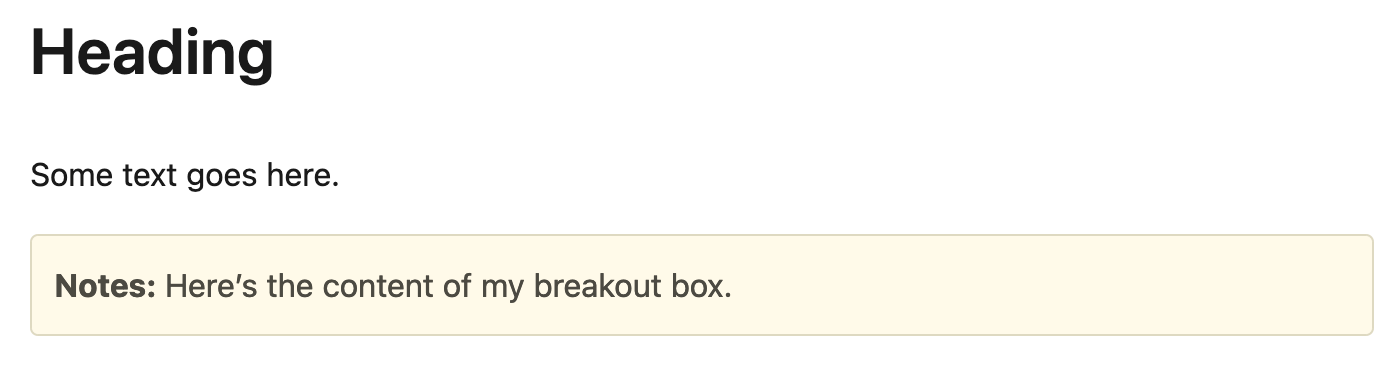
Great. 3 But, if we want to output our document as anything else, this won’t work. Under the hood, Pandoc is still applying the ’notes’ label to our element in the AST, but that label doesn’t mean anything to the other output formats. Instead, we can use a filter to add the required information to style these boxes in other output formats, without having to change our input syntax.
For Word/docx output, Pandoc does let you apply a custom label to a fenced div, and will then map that onto a style with the same name in your Word reference doc. We could just change our syntax and write our source document like this:
# Heading
Some text goes here.
::: {.notes custom-style="notes"}
Here's the content of my breakout box.
:::
Here, we’re still applying the ‘.notes’ class in HTML (we have to include a period in front of it now though, as we’ve switched to use the bracketed divs syntax) but also declaring a custom-style of ’notes’ that, if we have the corresponding style in our Word reference doc, Pandoc will apply to the content of the div.
This is okay, but it’s nowhere near as convenient as the first example’s syntax. Why not stick with that, and instead have the filter add in the extra syntax for us instead?
After all, the whole point of all this effort is to keep the output syntax completely divorced from the input syntax, so you can export to any format you might need at a later time. If I start filling my Markdown with code aimed specifically at Word outputs, it defeats the purpose of using a tool like Pandoc in the first place!
In the filter file (using the .lua extension), we can define a function named Div and pass in our element. In this case, we’re passing in everything contained within the div - so a nested series of paragraphs, and within each of those, any inline elements. You could drill down and access those if you needed, but for our purposes, we just want to add an extra attribute to the div:
function Div (elem)
if FORMAT:match 'docx' then
if elem.classes[1] == "notes" then
elem.attributes['custom-style'] = 'Notes'
return elem
else
return elem
end
end
end
FORMAT is a global variable in a filter that just contains the output format currently being generated. Here, all we’re saying is:
- If the output is docx, look at each div within the document.
- For each div, see if it has the class ’notes’ with
elem.classes[1]. 4 - If a div has the class ’notes’, then also add a new attribute named ‘custom-style’ with the content ‘Notes’ and return the new div.
- Otherwise, just return the original div.
Now, provided we have the style ‘Notes’ setup in our Word reference doc, it will automatically get assigned to our div in the output!

Importantly, if we switch our output back to HTML, it makes no difference - the class is just applied to the div as before, and the filter skips over the function as FORMAT doesn’t match docx.
Now, let’s also look at PDF output. Pandoc uses LaTeX as an intermediary to generate PDF files. Unfortunately there’s no way (I know of) to apply custom styling to LaTeX output natively in Pandoc that doesn’t involve just filling your source doc with actual LaTeX. At which point you might as well just… write LaTeX. Instead, we can use a filter to find our notes div as before, and wrap some custom LaTeX commands around the div contents instead.
I used the LaTeX package tcolorbox for this. The precise mechanisms of tcolorbox aren’t the main point here, but if you want to use it exactly as I have you’ll need to customise the LaTeX template to include tcolorbox as a package. Easiest way I found was to just put \usepackage{tcolorbox} in the LaTeX preamble as detailed here.
I also use some dvipsnames colour names in the code from xcolor with \usepackage[dvipsnames]{xcolor} so I can create shades of colours, but having recently stumbled over defining your own colours in LaTeX I might just swap these out for some good ol’ RGB values in the future. Hey, have you heard of the colour ‘Cosmic Latte’? (Thanks, Robin Sloan)
Anyway.
Here’s the filter code:
function Div (elem)
if FORMAT:match 'latex' then
if elem.classes[1] == "notes" then
return {
pandoc.RawBlock('latex', '\\begin{tcolorbox}[colframe=Apricot!20!white, colback=Apricot!8!white]'),
elem,
pandoc.RawBlock('latex', '\\end{tcolorbox}')
}
else
return elem
end
end
end
This works much like the Word filter:
- If the output is LaTeX, look at each div in the document.
- See if each div has the class ’notes’.
- If it does, create and return a new Block element.
- This Block element will contain some raw LaTeX code, followed by the entire original div itself (elem), followed again by some more raw LaTeX.
- Otherwise, return the original div.
pandoc.RawBlock is what allows us to write some raw code in the language our output format uses - in this case, LaTeX. So the function basically ends up wrapping a \begin{tcolorbox} and \end{tcolorbox} around our div and, when output to PDF, the div is now surrounded by the LaTeX code required to create a coloured box!

And again, if we switch back to HTML, Pandoc just ignores this function and our output looks the same as before.
We can combine these two functions into one:
function Div (elem)
if FORMAT:match 'docx' then
if elem.classes[1] == "notes" then
elem.attributes['custom-style'] = 'Notes'
return elem
else
return elem
end
elseif FORMAT:match 'latex' then
if elem.classes[1] == "notes" then
return {
pandoc.RawBlock('latex', '\\begin{tcolorbox}[beforeafter skip=1cm, ignore nobreak=true, breakable, colframe=Apricot!20!white, colback=Apricot!8!white, boxsep=2mm, arc=0mm, boxrule=0.5mm]'),
elem,
pandoc.RawBlock('latex', '\\end{tcolorbox}')
}
else
return elem
end
end
end
I’ve since thought of a more streamlined way of doing this that doesn’t involve writing an ‘if’ statement for each type of box you’d like to create - see the edit at the end of this post.
Now we can use fenced divs with ::: notes with abandon in our original Markdown doc, and not worry about how it’s going to come out in our output format - no matter which we choose, it’ll be formatted as a coloured box.
Using with Bookdown/Rmarkdown
To use the filter with Bookdown/Rmarkdown, save it as a .lua file and place it somewhere convenient within your Bookdown project. I use filters/shortcodes.lua.
The most straightforward way I found to use the filter was to just tell Pandoc about it directly when we issue the command to build our document. In your _output.yml, just pass the filter as an extra argument to Pandoc using pandoc_args and --lua-filter. 5 You’ll need to include it for each output you want:
bookdown::pdf_document2:
toc: false
pandoc_args: ["--lua-filter", "filters/shortcodes.lua"]
bookdown::word_document2:
reference_docx: "assets/ref-doc.docx"
pandoc_args: ["--lua-filter", "filters/shortcodes.lua"]
Obviously you’ll also need to modify any of the surrounding files affected - maybe some custom CSS, or the Word reference doc, or the LaTeX template. 6
Once you get the hang of these filters, you can easily start applying all sorts of custom styling to your outputs from these fenced divs. You could very quickly add mores fenced div to this example - say, ::: warning, that produces red styled boxes. That’s on you though as this post has gone on long enough!
Thanks for reading, I hope it’s been even a tiny bit helpful. Get in touch if you’ve got any Pandoc/Bookdown tips of your own to share!
Edit: Another method
Since writing this post, I’ve also realised another way of applying these filters that doesn’t involve writing endless ‘if’ statements in your filter. Here’s the new function:
function Div (elem)
if FORMAT:match 'docx' then
if elem.classes[1] then
elem.attributes['custom-style'] = elem.classes[1]
return elem
else
return elem
end
elseif FORMAT:match 'latex' then
if elem.classes[1] then
local box = "\\begin{tcolorbox}[colframe=" .. elem.classes[1] .. "-frame, colback=" .. elem.classes[1] .. "-bg]"
return{
pandoc.RawBlock('latex', box),
elem,
pandoc.RawBlock('latex', '\\end{tcolorbox}')
}
else
return elem
end
end
end
It’s not that different, but instead of explicitly assigning custom-styles in the docx we just apply elem.classes[1] directly. As before, as long as your Word reference doc contains a style named the same as the div you create, it’ll map over just fine. But this way, you can just create the styles in your Word reference doc and start applying them in your Markdown without having to touch the filter.
For PDF/LaTeX, the function now creates a string (with the extremely weird Lua string concatenation operator ..) that sets the colours in tcolorbox to a name matching the div name, with ‘-bg’ and ‘-frame’ appended to distinguish box background and border colours. The idea is similar - you can now just create the colours in your LaTeX template/preamble and start applying them in your Markdown without having to touch the filter, like so:
\definecolor{notes-bg}{RGB}{255, 248, 231}
\definecolor{notes-frame}{RGB}{255, 248, 231}
Or, you could always take out the ‘-bg’ and ‘-frame’ bits, and just give your divs the same names as some of the colour names LaTeX has built in.
These changes mean you can basically just leave the filter alone and create your styles/colours elsewhere to incorporate them, just as with the HTML/CSS output.
Just be a little careful, as this will apply to all divs in Pandoc - so if you’re creating a PowerPoint presentation for example, and you use the ::: incremental div to create incremental bullet points in your slides, then this filter will also try and apply the styles/colours ‘incremental’ to your output docs in Word/PDF formats. Word will just ignore any styles it doesn’t find in your reference doc, but this can stall PDF creation completely, so be ready to work round it or go back to the original elem.classes[1] == 'notes' method in the filter.
-
You might have already used one of these without realising - Rmarkdown uses a Pandoc filter to let you use the LaTeX command
\newpagein your Markdown to force a page-break, even if your output format isn’t LaTeX/PDF. If you look, you can spot it in the command line arguments sent over to Pandoc when you build your book. ↩︎ -
Don’t forget this is in the AST, after Pandoc has read in and translated your source doc. So it doesn’t matter if the source was Markdown defined with
**asterisks**, or HTML defined with<strong>tags</strong>. At this point, it’s all justPandoc.Strongin the AST. ↩︎ -
If you noticed and wondered - I used
::beforeto add the text ‘Notes:’ in front of the first paragraph within each div with the class ’notes’. Custom CSS styling for your output is also bonkers-crazy-useful, but that’s another post. ↩︎ -
Pandoc will have already assigned it to our div from the fenced div syntax without us needing to do anything extra. ↩︎
-
If you want to get really fancy, you could create a custom Rmarkdown format to knit to that includes the filter by default - see here for more. ↩︎
-
I haven’t tried this with
gitbookoutput yet, but in theory you can just inject the CSS for the breakout box into that and it should work fine. ↩︎
